Word wrapping
One of the core properties of most good coding interview questions, for me, is
that they take some input, transform it, and produce output that is “better” in
some meaningful way. It occurred to me the other day that one of the simplest
examples of this would have to be a word-wrapping function. That said, I had
never written one, so I decided to try it in somewhat of an interview setting,
giving myself half an hour with no advanced thought. I first defined a few
tests, which I refer to as TESTS in my program. I’ve written them here
prepended by ---, to show where one test ends and the next begins.
---
This is a very long, single line test string that I would like to see wrapped to 80 characters per line, in accordance with international law and general human decency.
---
This is a string
that is _less_ than 80 characters.
Crazy, right?
---
This string has...
...lots of newlines.
I've decided just to keep one newline between paragraphs, but this is definitely debateable and something that could be configured as an option in the future. Boy, how I drone on when I'm trying to make a long line.
---
This string has lots of extra spaces. It should end up as one line.
---
This is a string with oneExtremelyLongWord.AllWeCanDoHereIsPrintThisThingOnItsOwnLineAndWrapTheRestOfTheParagraphAroundIt.ThereIsNotAnyOtherGreatWayToHandle this that I can think of.
So, yeah, coming up with long strings is hard. Anyway, here’s the code I wrote.
import re
TESTS = <tests listed above>
def unwrap(s):
paragraphs = re.split("\n\n+", s)
unwrapped = []
for para in paragraphs:
if para:
unwrapped.append(para.replace("\n", " "))
return unwrapped
def wrap(s, width=80):
words = re.split(" +", s)
lines = []
line = ""
for word in words:
if len(line) + len(word) <= width:
line = line + " " + word
else:
lines.append(line.strip())
line = word
if line:
lines.append(line.strip())
return "\n".join(lines)
def fmt(s):
unwrapped = unwrap(s)
wrapped = []
for para in unwrapped:
wrapped.append(wrap(para))
return "\n\n".join(wrapped)
def main():
for test in TESTS:
print("---")
print(fmt(test))
if __name__ == "__main__":
main()
My natural inclination was to break down the problem into components and do some pre-processing (splitting paragraphs and turning each into one line, in this case). I always want to consider multiple ways to solve any interview question, so I decided to take another fifteen minutes and try a streaming approach, storing at most one line of data at any time. Once I started down that path, I realized that I was thinking in terms of a state machine, and decided to draw one out.
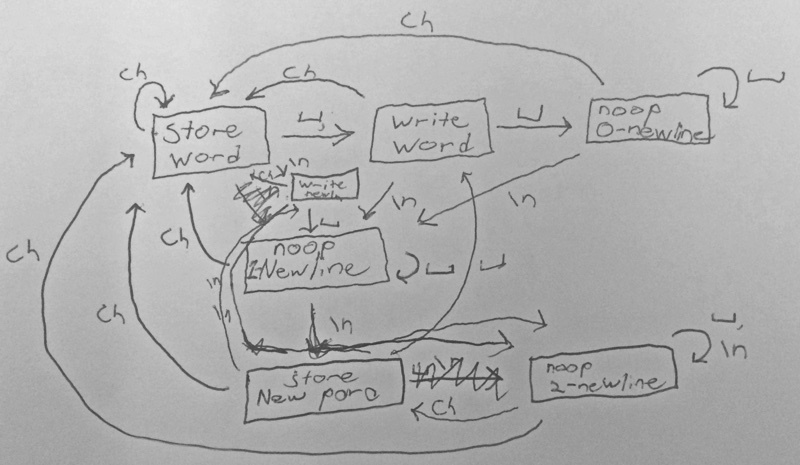
Once I had defined my states and transitions, the actual logic to perform at each step was easy. I only needed to store one word and the line length, not even the whole line. Here’s the code I wrote.
from enum import Enum, auto
import sys
TESTS = <tests listed above>
class States(Enum):
START = auto()
STORE = auto()
WRITE_SPACE = auto()
WRITE_NEWLINE = auto()
NOOP_0 = auto()
NOOP_1 = auto()
NOOP_2 = auto()
WRITE_NEW_PARA = auto()
WRITE_END = auto()
END = auto()
class Inputs(Enum):
SPACE = auto()
NEWLINE = auto()
CHAR = auto()
END = auto()
def next_with_type(si):
try:
ch = next(si)
if ch == " ":
return (ch, Inputs.SPACE)
if ch == "\n":
return (ch, Inputs.NEWLINE)
return (ch, Inputs.CHAR)
except StopIteration:
return ("", Inputs.END)
def transition(state, ch):
if state == States.START:
if ch == Inputs.SPACE:
return States.START
if ch == Inputs.NEWLINE:
return States.START
if ch == Inputs.CHAR:
return States.STORE
if ch == Inputs.END:
return State.END
if state == States.STORE:
if ch == Inputs.SPACE:
return States.WRITE_SPACE
if ch == Inputs.NEWLINE:
return States.WRITE_NEWLINE
if ch == Inputs.CHAR:
return States.STORE
if ch == Inputs.END:
return States.WRITE_END
if state == States.WRITE_SPACE:
if ch == Inputs.SPACE:
return States.NOOP_0
if ch == Inputs.NEWLINE:
return States.NOOP_1
if ch == Inputs.CHAR:
return States.STORE
if ch == Inputs.END:
return States.END
if state == States.WRITE_NEWLINE:
if ch == Inputs.SPACE:
return States.NOOP_1
if ch == Inputs.NEWLINE:
return States.NOOP_2
if ch == Inputs.CHAR:
return States.STORE
if ch == Inputs.END:
return States.END
if state == States.NOOP_0:
if ch == Inputs.SPACE:
return States.NOOP_0
if ch == Inputs.NEWLINE:
return States.NOOP_1
if ch == Inputs.CHAR:
return States.STORE
if ch == Inputs.END:
return States.END
if state == States.NOOP_1:
if ch == Inputs.SPACE:
return States.NOOP_1
if ch == Inputs.NEWLINE:
return States.NOOP_2
if ch == Inputs.CHAR:
return States.STORE
if ch == Inputs.END:
return States.END
if state == States.NOOP_2:
if ch == Inputs.SPACE:
return States.NOOP_2
if ch == Inputs.NEWLINE:
return States.NOOP_2
if ch == Inputs.CHAR:
return States.WRITE_NEW_PARA
if ch == Inputs.END:
return States.END
if state == States.WRITE_NEW_PARA:
if ch == Inputs.SPACE:
return States.WRITE_SPACE
if ch == Inputs.NEWLINE:
return States.WRITE_NEWLINE
if ch == Inputs.CHAR:
return States.STORE
if ch == Inputs.END:
return States.WRITE_END
if state == States.WRITE_END:
return States.END
def fmt(si, width=80):
word = ""
curlen = 0
state = States.START
while True:
ch, tp = next_with_type(si)
state = transition(state, tp)
if state == States.STORE:
word += ch
if state == States.WRITE_SPACE or state == States.WRITE_NEWLINE or state == States.WRITE_END:
if curlen + len(word) + 1 > width:
sys.stdout.write("\n")
curlen = 0
if curlen > 0:
sys.stdout.write(" ")
curlen += 1
sys.stdout.write(word)
curlen += len(word)
word = ""
if state == States.WRITE_NEW_PARA:
sys.stdout.write("\n\n")
word = ch
curlen = 0
if state == States.END:
sys.stdout.write("\n")
break
def main():
for test in TESTS:
print("---")
fmt(iter(test))
if __name__ == "__main__":
main()
This code is longer than my first attempt, but a more compact representation of the transition matrix (like, say, an actual matrix, 2-D array, or dict of dicts) would go a long way toward fixing that. I’m guilty of producing the occasional messy piece of code during an interview, just like anyone. I think the important thing in interviews is to recognize those problems and explain how you would fix them (as long as the problems aren’t too major!). Finally, although it’s pretty easy to imagine, I’ll give the output of this program.
---
This is a very long, single line test string that I would like to see wrapped to
80 characters per line, in accordance with international law and general human
decency.
---
This is a string that is _less_ than 80 characters.
Crazy, right?
---
This string has...
...lots of newlines.
I've decided just to keep one newline between paragraphs, but this is definitely
debateable and something that could be configured as an option in the future.
Boy, how I drone on when I'm trying to make a long line.
---
This string has lots of extra spaces. It should end up as one line.
---
This is a string with
oneExtremelyLongWord.AllWeCanDoHereIsPrintThisThingOnItsOwnLineAndWrapTheRestOfTheParagraphAroundIt.ThereIsNotAnyOtherGreatWayToHandle
this that I can think of.